
はじめに
前回はPostgreSQLを設定しました。DBを起動すればストーミングレプリケーションによる冗長構成が出来ていますが、障害発生時に自動で切り替わりません。ZabbixのDBがダウンすることは監視サーバの停止を意味するので、許容される可能性は少ないでしょう。片方がダウンしてもサービスを継続できるように、PacemakerでVIPを持たせます。勝手な思いで恐縮ですが、個人的にPacamakerでPostgreSQLを起動させるために四苦八苦した経験があります。特に後半に自身がはまったところを書いたので、読んでいただいた方に何かしらのヒントをお伝えられれば幸いです。
構成図
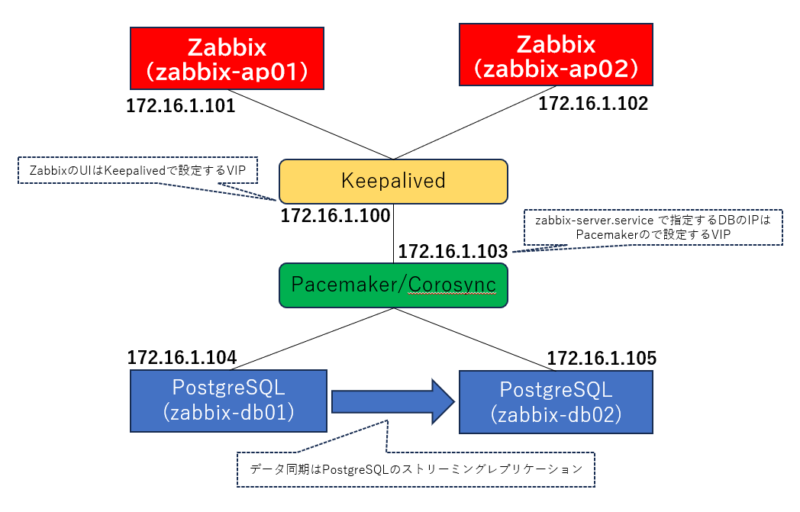
ホスト名:zabbix-ap01
IP:172.16.1.101
構成:AlmaLinux 9、Zabbix6.0
ホスト名:zabbix-ap02
IP:172.16.1.102
構成:AlmaLinux 9、Zabbix6.0
ホスト名:zabbix-db01
IP:172.16.1.104
構成:AlmaLinux 9、PostgreSQL 13
ホスト名:zabbix-db02
IP:172.16.1.105
構成:AlmaLinux 9、PostgreSQL 13
パッケージインストール
実施するサーバ:zabbix-db01、zabbix-db02
以下のコマンドでリポジトリを確認します。
# dnf repolist all |grep ha
highavailability AlmaLinux 9 - HighAvailability disabled
highavailability-debuginfo AlmaLinux 9 - HighAvailability - Debug disabled
highavailability-source AlmaLinux 9 - HighAvailability - Sourc disabled
saphana AlmaLinux 9 - SAPHANA disabled
saphana-debuginfo AlmaLinux 9 - SAPHANA - Debug disabled
saphana-source AlmaLinux 9 - SAPHANA - Source disabled以下のコマンドでpacemaker をインストールします。
# dnf --enablerepo=highavailability install pacemaker pcs fence-agents-all pcp-zeroconf -yインストールが無事に完了した後、ログ設定を先に済ませておきましょう。ログは予め作成していたディレクトリを指定しておきます。
# cp -p /etc/sysconfig/pacemaker{,org}
# cat <<_EOF_>> /etc/sysconfig/pacemaker
#add setting
PCMK_debug=no
PCML_logfile=/var/log/pacemaker/pacemaker.log
PCMK_logpriority=notice
_EOF_クラスター用のユーザを作成します。
# passwd haclusterpcsサービスを起動し、ついでに自動起動設定も行います。
# systemctl start pcsd.service
# systemctl enable pcsd.service注意
AlmaLinuxでインストールする場合はこれで良いですが、RHELでPacemakerを使う場合は、以下のコマンドになります。ha用のライセンス購入も必要になりますので、導入する場合は事前に見積もっておく必要があります。
# subscription-manager repos --enable=rhel-9-for-x86_64-highavailability-rpms
# dnf install pcs pacemaker fence-agents-allPacemaker設定
実施するサーバ:zabbix-db01
ここから先は片方のDBでのみ実施していきます。まず、Pacemaker用のホストを認証します。このとき、先ほど作成したクラスター用のユーザで認証を行います。
クラスター作成
# pcs host auth zabbix-db01 addr=172.16.1.104 zabbix-db02 addr=172.16.1.105
Username: hacluster
Password:
zabbix-db01: Authorized
zabbix-db02: Authorized認証完了後、以下のコマンドでクラスターをスタートさせます。zabbixdbClusterという名前で起動させていますが、名前は自由です。また、名前解決が出来る場合はaddrを省略できるらしいですが、私は入れてます。何回か検証してうまくいった結果を本記事としていますので、ご了承ください。
# pcs cluster setup zabbixdbCluster --start zabbix-db01 addr=172.16.1.104 zabbix-db02 addr=172.16.1.105pcsコマンドを用いた設定
ここからはpcsコマンドによる設定を入れていきます。
最初はPacemakerの初期設定みたいなものを入れていきます。
# pcs property set no-quorum-policy="ignore"pcs property set no-quorum-policy="ignore"
# pcs property set stonith-enabled="false"pcs property set stonith-enabled="false"
# pcs resource defaults update resource-stickiness="INFINITY"pcs resource defaults update resource-stickiness="INFINITY"
Warning: Defaults do not apply to resources which override them with their own defined values
# pcs resource defaults update migration-threshold="1"pcs resource defaults update migration-threshold="1"
Warning: Defaults do not apply to resources which override them with their own defined values次に、CIB(クラスター情報ベース)というファイルに設定を投入していきます。このCIBにPacamaker設定を入れ込み、最後にCIBをプッシュして反映させるイメージです。今回は、cluster-confという名前のファイルに入れることにしています。
# pcs cluster cib cluster-conf以後のコマンドには「pcs -f cluster-conf」がつきます。先ほどの説明の通り、「cluster-conf」に書き込んでいることを示しています。
まず、以下コマンドを投入します。
このコマンドはPacemakerのノードと172.16.1.1との疎通性を監視するための設定を入れています。172.16.1.1は今回構築するDBのゲートウェイです。つまり、DBとゲートウェイ間の疎通性を見ることになります。
# pcs -f cluster-conf resource create pingChk ocf:pacemaker:ping name=pingattr host_list=172.16.1.1vip用の設定をCIBに投入します。ip=”172.16.1.103″とあるように、VIPにしたいIPはここで指定します。
# pcs -f cluster-conf resource create vip-master ocf:heartbeat:IPaddr2 \
ip="172.16.1.103" \
nic="ens192" \
cidr_netmask="24" \
op start timeout="60s" interval="0s" on-fail="restart" \
op monitor timeout="60s" interval="10s" on-fail="restart" \
op stop timeout="60s" interval="0s" on-fail="block"PostgreSQL、すなわちDB用の設定を入れます。ところどころPostgreSQLの設定値があると思いますので、環境に応じて変更してください。
# pcs -f cluster-conf resource create prmPostgresql ocf:heartbeat:pgsql \
rep_mode="sync" \
node_list="zabbix-db01 zabbix-db02" \
pgctl=/usr/pgsql-13/bin/pg_ctl \
pgdata=/var/lib/pgsql/13/data \
restore_command="cp /var/lib/pgsql/13/pg_archive/%f %p" \
primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" \
master_ip="172.16.1.103" \
repuser="repuser" \
restart_on_promote='true' \
stop_escalate=0 \
xlog_check_count=0 \
op start timeout="30s" interval="0s" on-fail="restart" \
op monitor timeout="15s" interval="5s" on-fail="restart" \
op monitor timeout="15s" interval="3s" on-fail="restart" role="Promoted" \
op promote timeout="30s" interval="0s" on-fail="restart" \
op demote timeout="30s" interval="0s" on-fail="block" \
op notify timeout="60s" interval="0s" \
op stop timeout="30s" interval="0s" on-fail="block"作成したリソースの制約設定を投入します。
# pcs -f cluster-conf resource clone pingChk
# pcs -f cluster-conf resource promotable prmPostgresql master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
# pcs -f cluster-conf constraint colocation add vip-master with Promoted prmPostgresql-clone INFINITY
# pcs -f cluster-conf constraint order promote prmPostgresql-clone then start vip-master symmetrical=false score=INFINITY
# pcs -f cluster-conf constraint order demote prmPostgresql-clone then stop vip-master symmetrical=false score=0
# pcs -f cluster-conf constraint location prmPostgresql-clone rule score=-INFINITY pingattr lt 1 or not_defined pingattr
# pcs -f cluster-conf constraint colocation add prmPostgresql-clone with pingChk-clone score=INFINITY
# pcs -f cluster-conf constraint order pingChk-clone then prmPostgresql-clone symmetrical=falseCIB情報をプッシュします。プッシュすることで設定が反映されます。
# pcs cluster cib-push cluster-confPacemakerの起動とDBについて
次のコマンドでクラスターの状態を確認できます。–fullをつけると、詳細情報を取得できます。
# pcs status --full
Cluster name: zabbixdbCluster
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-09-10 15:32:20 +09:00)
Cluster Summary:
* Stack: corosync
* Current DC: zabbix-db02 (2) (version 2.1.5-9.el9_2-a3f44794f94) - partition with quorum
* Last updated: Sun Sep 10 15:32:20 2023
* Last change: Sun Sep 10 15:31:49 2023 by root via crm_attribute on zabbix-db02
* 2 nodes configured
* 5 resource instances configured
Node List:
* Node zabbix-db01 (1): online, feature set 3.16.2
* Node zabbix-db02 (2): online, feature set 3.16.2
Full List of Resources:
* vip-master (ocf:heartbeat:IPaddr2): Started zabbix-db02
* Clone Set: pingChk-clone [pingChk]:
* pingChk (ocf:pacemaker:ping): Started zabbix-db02
* pingChk (ocf:pacemaker:ping): Started zabbix-db01
* Clone Set: prmPostgresql-clone [prmPostgresql] (promotable):
* prmPostgresql (ocf:heartbeat:pgsql): Promoted zabbix-db02
* prmPostgresql (ocf:heartbeat:pgsql): Unpromoted zabbix-db01
Node Attributes:
* Node: zabbix-db01 (1):
* master-prmPostgresql : 100
* pingattr : 1
* prmPostgresql-data-status : STREAMING|SYNC
* prmPostgresql-status : HS:sync
* Node: zabbix-db02 (2):
* master-prmPostgresql : 1000
* pingattr : 1
* prmPostgresql-data-status : LATEST
* prmPostgresql-master-baseline : 00000000060000A0
* prmPostgresql-status : PRI
Migration Summary:
Tickets:
PCSD Status:
zabbix-db01: Online
zabbix-db02: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled上記はdb02が主系としてDBが起動していて、db01はストーミングレプリケーションで同期がとれていることを示しています。db02がなぜ主系?という疑問があるかと思いますが、今回検証した際の結果をあえてそのまま載せています。
どうやら起動のタイミングを誤ったか何かでPacemakerの判定がずれてしまったようです。気を付けていてもPacemakerの中で主副がずれることがあり、実際に検証でもそうなってしまったので、この結果を載せることにしました。
こうなった場合は、db02を手動で停止させて入れ替えてあげましょう。入れ替える場合はDBを停止させて、DBを再度主系からコピーするお決まりの手順を実施します。このあたりの手順もどこかで紹介できればと思います。(知っている人にとっては簡単な手順のせいか、ナレッジは少ない気がします)
この状態で主系のIPを確認すると、172.16.1.103のIPを持っていることを確認できます。これで、無事にVIPを持たせることができました。是非片方を停止させて、VIPが移るところを観察してみてください。
その他
あとは上記で説明されていない部分について、補足しておきます。
①DBは手動で起動しない
お気づきかもしれませんが、pg_ctl コマンドで起動していないのに、いつの間にかDBが起動していましたね。PacemakerでPostgreSQLを管理する場合、Pacemakerの起動と同時にDB起動をPacamakerが実行されます。この事実は構築経験者にとっては当たり前のような部分はあるものの、初めて触る人にとっては最初に知っておきたいことかと思います。当り前のこととして扱われているようで、ネット上の情報ではあまり説明してくれないです。
②postgresql.auto.confにご用心
postgresql.auto.confって何よ?という方は別途調べてください。
PostgreSQLの構築・検証を初めてする場合、Pacemakerの前にPostgreSQL自体の構築や検証をするかと思います。そうすると、「PostgreSQL ストーミングレプリケーション」で構築方法を調べますね。それは別に問題ないです(理解が足りない部分は、是非とも検証してください!)ただ、主系を構築した後、副系はpg_basebackupコマンドで複製してそのままレプリケーションに組み込んじゃう訳ですが、よくこんなコマンドが紹介されています。
pg_basebackup -R -D ${PGDATA} -h [マスターDBのIP]何が悪いかというと、この「-R」です。これがpostgresql.auto.confに設定情報を書き込んでくれるわけです。
例としてはこんな感じです。
# cat /var/lib/pgsql/13/data/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
primary_conninfo = 'user=postgres passfile=''/var/lib/pgsql/.pgpass'' channel_binding=prefer host=172.16.1.104 port=5432 sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=any'このおかげでDBを手動起動させた際には問題なくレプリケーションしてくれますが、このpostgresql.auto.confがある状態だと、PacemakerのDB起動時に同期されずに失敗します。「PostgreSQLを手動起動時は成功するのに…なぜ」という感じで、原因が分からず苦労しました。
正解はPacemakerで起動させた際に、DBに自動作成されるrecobery.confにあります。以下の通りになります。上との違いは、「host=172.16.1.XXX」の部分です。Pacemakerで起動するときは、VIPを指定するんですね。結論としては、「-R」オプションはつけないことが正解で、Pacemaker起動時に自動作成されることを信じてあげる必要があります。
# cat /var/lib/pgsql/tmp/recovery.conf
primary_conninfo = 'host=172.16.1.103 port=5432 user=repuser application_name=zabbix-db02-keepalives_idle=60 keepalives_interval=5 keepalives_count=5'
restore_command = 'cp /var/lib/pgsql/13/pg_archive/%f %p'
recovery_target_timeline = 'latest'このことに気が付かなかったせいでけっこうはまりました。おかげでPacemakerのログもずいぶん読むことになって理解を深められましたが…気が付くまで生きた心地がしなかったですね。同じはまり方をしている方の手助けになれば幸いです。
長くなりましたが、次回はZabbixの設定です。

